The Falcon has landed in the Hugging Face ecosystem














This article is also available in Chinese 简体中文.
Falcon is a new family of state-of-the-art language models created by the Technology Innovation Institute in Abu Dhabi, and released under the Apache 2.0 license. Notably, Falcon-40B is the first “truly open” model with capabilities rivaling many current closed-source models. This is fantastic news for practitioners, enthusiasts, and industry, as it opens the door for many exciting use cases.
Note: Few months after this release, the Falcon team released a larger model of 180 billion parameters.
In this blog, we will be taking a deep dive into the Falcon models: first discussing what makes them unique and then showcasing how easy it is to build on top of them (inference, quantization, finetuning, and more) with tools from the Hugging Face ecosystem.
Table of Contents
The Falcon models
The Falcon family is composed of two base models: Falcon-40B and its little brother Falcon-7B. The 40B parameter model was at the top of the Open LLM Leaderboard at the time of its release, while the 7B model was the best in its weight class.
Note: the performance scores shown in the table below have been updated to account for the new methodology introduced in November 2023, which added new benchmarks. More details in this post.
Falcon-40B requires ~90GB of GPU memory — that’s a lot, but still less than LLaMA-65B, which Falcon outperforms. On the other hand, Falcon-7B only needs ~15GB, making inference and finetuning accessible even on consumer hardware. (Later in this blog, we will discuss how we can leverage quantization to make Falcon-40B accessible even on cheaper GPUs!)
TII has also made available instruct versions of the models, Falcon-7B-Instruct and Falcon-40B-Instruct. These experimental variants have been finetuned on instructions and conversational data; they thus lend better to popular assistant-style tasks. If you are just looking to quickly play with the models they are your best shot. It’s also possible to build your own custom instruct version, based on the plethora of datasets built by the community—keep reading for a step-by-step tutorial!
Falcon-7B and Falcon-40B have been trained on 1.5 trillion and 1 trillion tokens respectively, in line with modern models optimising for inference. The key ingredient for the high quality of the Falcon models is their training data, predominantly based (>80%) on RefinedWeb — a novel massive web dataset based on CommonCrawl. Instead of gathering scattered curated sources, TII has focused on scaling and improving the quality of web data, leveraging large-scale deduplication and strict filtering to match the quality of other corpora. The Falcon models still include some curated sources in their training (such as conversational data from Reddit), but significantly less so than has been common for state-of-the-art LLMs like GPT-3 or PaLM. The best part? TII has publicly released a 600 billion tokens extract of RefinedWeb for the community to use in their own LLMs!
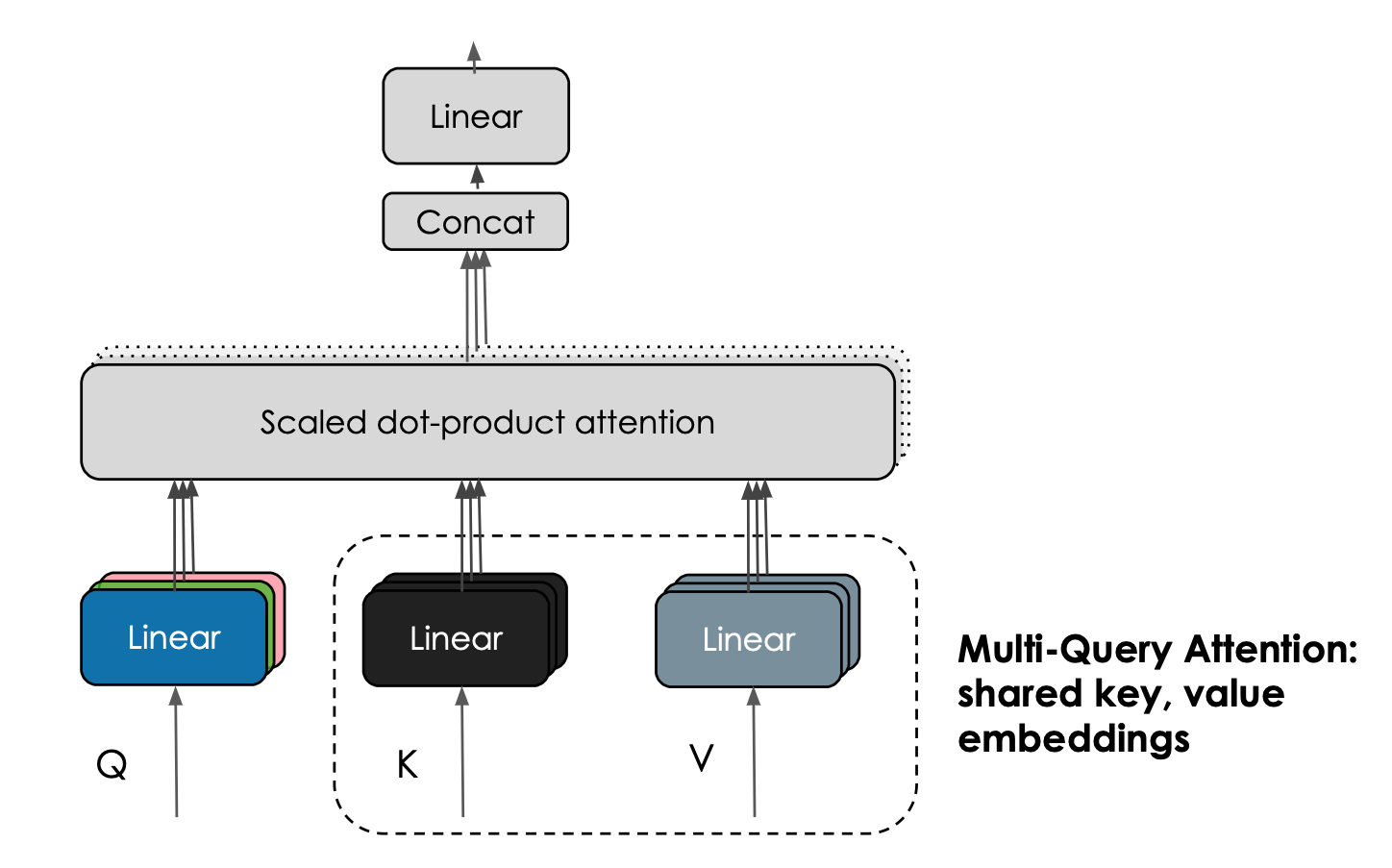
Another interesting feature of the Falcon models is their use of multiquery attention. The vanilla multihead attention scheme has one query, key, and value per head; multiquery instead shares one key and value across all heads.
 |
|---|
| Multi-Query Attention shares keys and value embeddings across attention heads. Courtesy Harm de Vries. |
This trick doesn’t significantly influence pretraining, but it greatly improves the scalability of inference: indeed, the K,V-cache kept during autoregressive decoding is now significantly smaller (10-100 times depending on the specific of the architecture), reducing memory costs and enabling novel optimizations such as statefulness.
| Model | License | Commercial use? | Pretraining length [tokens] | Pretraining compute [PF-days] | Leaderboard score | K,V-cache size for a 2.048 context |
|---|---|---|---|---|---|---|
| StableLM-Alpha-7B | CC-BY-SA-4.0 | ✅ | 1,500B | 700 | 34.37 | 800MB |
| LLaMA-7B | LLaMA license | ❌ | 1,000B | 500 | 45.65 | 1,100MB |
| MPT-7B | Apache 2.0 | ✅ | 1,000B | 500 | 44.28 | 1,100MB |
| Falcon-7B | Apache 2.0 | ✅ | 1,500B | 700 | 44.17 | 20MB |
| LLaMA-33B | LLaMA license | ❌ | 1,500B | 3200 | - | 3,300MB |
| LLaMA-65B | LLaMA license | ❌ | 1,500B | 6300 | 61.19 | 5,400MB |
| Falcon-40B | Apache 2.0 | ✅ | 1,000B | 2800 | 58.07 | 240MB |
Demo
You can easily try the Big Falcon Model (40 billion parameters!) in this Space or in the playground embedded below:
Under the hood, this playground uses Hugging Face's Text Generation Inference, a scalable Rust, Python, and gRPC server for fast & efficient text generation. It's the same technology that powers HuggingChat.
We've also built a Core ML version of the 7B instruct model, and this is how it runs on an M1 MacBook Pro:
The video shows a lightweight app that leverages a Swift library for the heavy lifting: model loading, tokenization, input preparation, generation, and decoding. We are busy building this library to empower developers to integrate powerful LLMs in all types of applications without having to reinvent the wheel. It's still a bit rough, but we can't wait to share it with you. Meanwhile, you can download the Core ML weights from the repo and explore them yourself!
Inference
You can use the familiar transformers APIs to run the models on your own hardware, but you need to pay attention to a couple of details:
- The models were trained using the
bfloat16datatype, so we recommend you use the same. This requires a recent version of CUDA and works best on modern cards. You may also try to run inference usingfloat16, but keep in mind that the models were evaluated usingbfloat16. - You need to allow remote code execution. This is because the models use a new architecture that is not part of
transformersyet - instead, the code necessary is provided by the model authors in the repo. Specifically, these are the files whose code will be used if you allow remote execution (usingfalcon-7b-instructas an example): configuration_RW.py, modelling_RW.py.
With these considerations, you can use the transformers pipeline API to load the 7B instruction model like this:
from transformers import AutoTokenizer
import transformers
import torch
model = "tiiuae/falcon-7b-instruct"
tokenizer = AutoTokenizer.from_pretrained(model)
pipeline = transformers.pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
torch_dtype=torch.bfloat16,
trust_remote_code=True,
device_map="auto",
)
And then, you'd run text generation using code like the following:
sequences = pipeline(
"Write a poem about Valencia.",
max_length=200,
do_sample=True,
top_k=10,
num_return_sequences=1,
eos_token_id=tokenizer.eos_token_id,
)
for seq in sequences:
print(f"Result: {seq['generated_text']}")
And you may get something like the following:
Valencia, city of the sun
The city that glitters like a star
A city of a thousand colors
Where the night is illuminated by stars
Valencia, the city of my heart
Where the past is kept in a golden chest
Inference of Falcon 40B
Running the 40B model is challenging because of its size: it doesn't fit in a single A100 with 80 GB of RAM. Loading in 8-bit mode, it is possible to run in about 45 GB of RAM, which fits in an A6000 (48 GB) but not in the 40 GB version of the A100. This is how you'd do it:
from transformers import AutoTokenizer, AutoModelForCausalLM
import transformers
import torch
model_id = "tiiuae/falcon-40b-instruct"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.bfloat16,
trust_remote_code=True,
load_in_8bit=True,
device_map="auto",
)
pipeline = transformers.pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
)
Note, however, that mixed 8-bit inference will use torch.float16 instead of torch.bfloat16, so make sure you test the results thoroughly.
If you have multiple cards and accelerate installed, you can take advantage of device_map="auto" to automatically distribute the model layers across various cards. It can even offload some layers to the CPU if necessary, but this will impact inference speed.
There's also the possibility to use 4-bit loading using the latest version of bitsandbytes, transformers and accelerate. In this case, the 40B model takes ~27 GB of RAM to run. Unfortunately, this is slightly more than the memory available in cards such as 3090 or 4090, but it's enough to run on 30 or 40 GB cards.
Text Generation Inference
Text Generation Inference is a production ready inference container developed by Hugging Face to enable easy deployment of large language models.
Its main features are:
- Continuous batching
- Token streaming using Server-Sent Events (SSE)
- Tensor Parallelism for faster inference on multiple GPUs
- Optimized transformers code using custom CUDA kernels
- Production ready logging, monitoring and tracing with Prometheus and Open Telemetry
Since v0.8.2, Text Generation Inference supports Falcon 7b and 40b models natively without relying on the Transformers "trust remote code" feature, allowing for airtight deployments and security audits. In addition, the Falcon implementation includes custom CUDA kernels to significantly decrease end-to-end latency.
 |
|---|
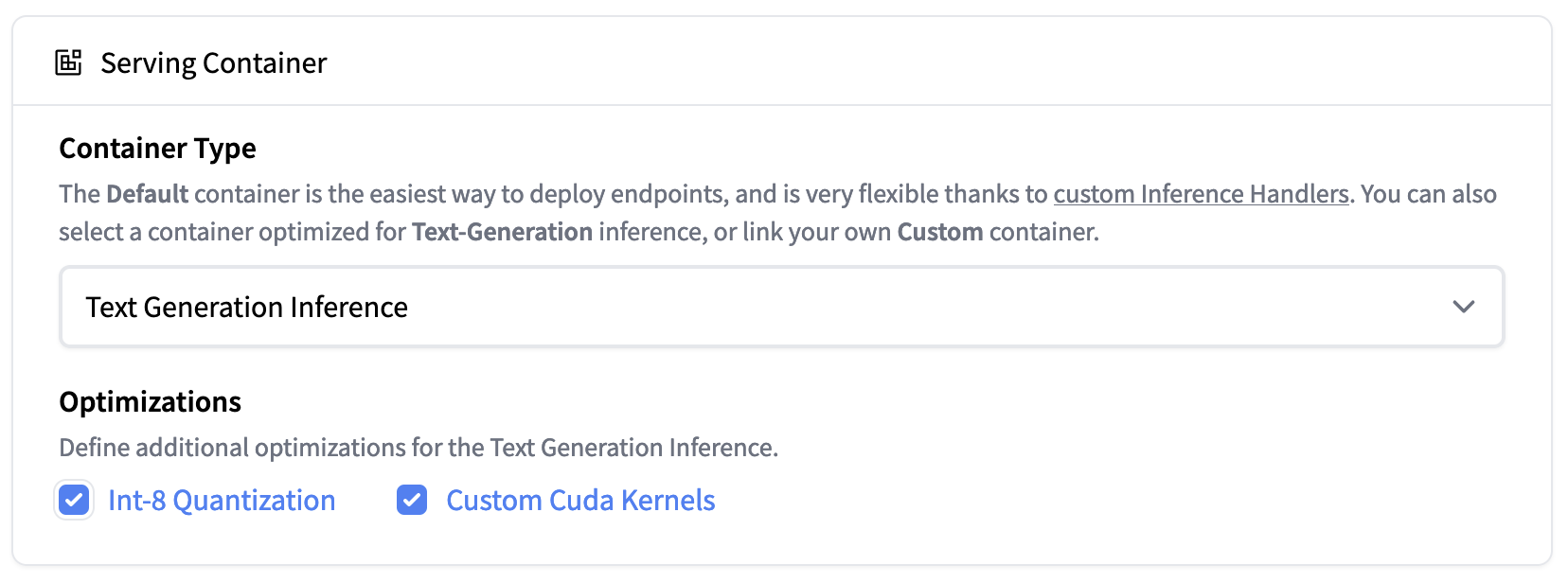
| Inference Endpoints now support Text Generation Inference. Deploy the Falcon 40B Instruct model easily on 1xA100 with Int-8 quantization |
Text Generation Inference is now integrated inside Hugging Face's Inference Endpoints. To deploy a Falcon model, go to the model page and click on the Deploy -> Inference Endpoints widget.
For 7B models, we advise you to select "GPU [medium] - 1x Nvidia A10G".
For 40B models, you will need to deploy on "GPU [xlarge] - 1x Nvidia A100" and activate quantization: Advanced configuration -> Serving Container -> Int-8 Quantization. Note: You might need to request a quota upgrade via email to api-enterprise@huggingface.co
Evaluation
So how good are the Falcon models? An in-depth evaluation from the Falcon authors will be released soon, so in the meantime we ran both the base and instruct models through our open LLM benchmark. This benchmark measures both the reasoning capabilities of LLMs and their ability to provide truthful answers across the following domains:
- AI2 Reasoning Challenge (ARC): Grade-school multiple choice science questions.
- HellaSwag: Commonsense reasoning around everyday events.
- MMLU: Multiple-choice questions in 57 subjects (professional & academic).
- TruthfulQA: Tests the model’s ability to separate fact from an adversarially-selected set of incorrect statements.
The results show that the 40B base and instruct models are very strong, and currently rank 1st and 2nd on the LLM leaderboard 🏆!
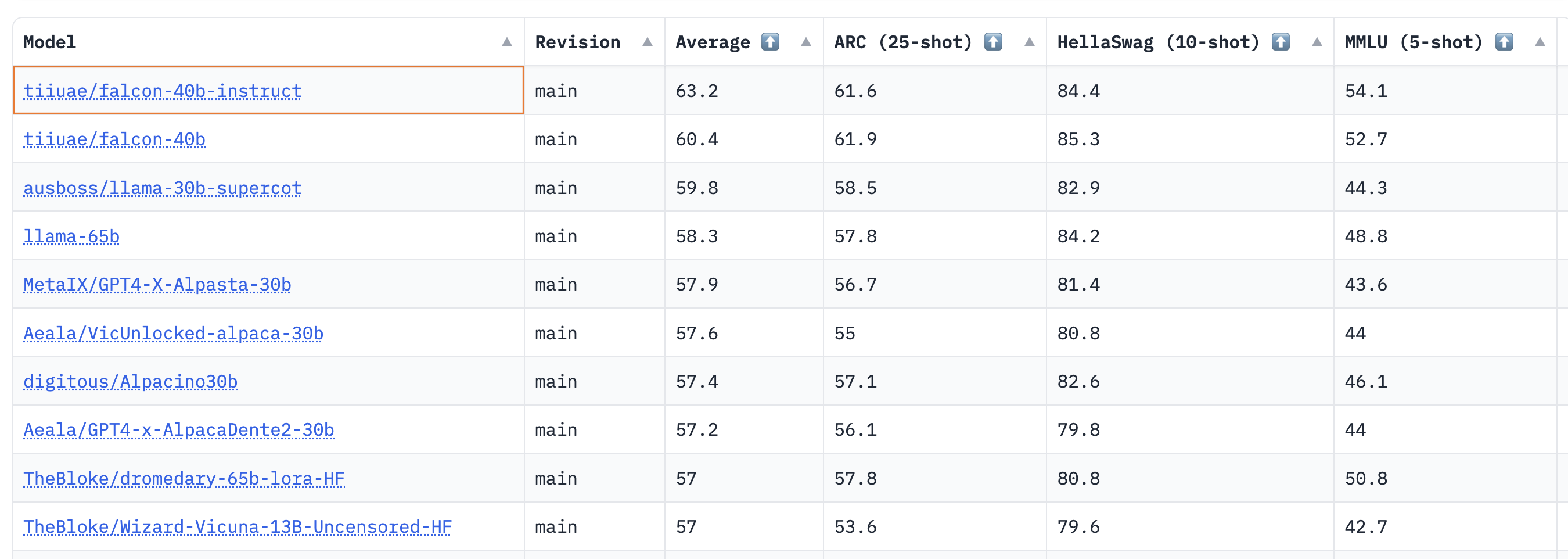
As noted by Thomas Wolf, one surprisingly insight here is that the 40B models were pretrained on around half the compute needed for LLaMa 65B (2800 vs 6300 petaflop days), which suggests we haven't quite hit the limits of what's "optimal" for LLM pretraining.
For the 7B models, we see that the base model is better than llama-7b and edges out MosaicML's mpt-7b to become the current best pretrained LLM at this scale. A shortlist of popular models from the leaderboard is reproduced below for comparison:
| Model | Type | Average leaderboard score |
|---|---|---|
| tiiuae/falcon-40b-instruct | instruct | 63.2 |
| tiiuae/falcon-40b | base | 60.4 |
| llama-65b | base | 58.3 |
| TheBloke/dromedary-65b-lora-HF | instruct | 57 |
| stable-vicuna-13b | rlhf | 52.4 |
| llama-13b | base | 51.8 |
| TheBloke/wizardLM-7B-HF | instruct | 50.1 |
| tiiuae/falcon-7b | base | 48.8 |
| mosaicml/mpt-7b | base | 48.6 |
| tiiuae/falcon-7b-instruct | instruct | 48.4 |
| llama-7b | base | 47.6 |
Although the open LLM leaderboard doesn't measure chat capabilities (where human evaluation is the gold standard), these preliminary results for the Falcon models are very encouraging!
Let's now take a look at how you can fine-tune your very own Falcon models - perhaps one of yours will end up on top of the leaderboard 🤗.
Fine-tuning with PEFT
Training 10B+ sized models can be technically and computationally challenging. In this section we look at the tools available in the Hugging Face ecosystem to efficiently train extremely large models on simple hardware and show how to fine-tune the Falcon-7b on a single NVIDIA T4 (16GB - Google Colab).
Let's see how we can train Falcon on the Guanaco dataset a high-quality subset of the Open Assistant dataset consisting of around 10,000 dialogues. With the PEFT library we can use the recent QLoRA approach to fine-tune adapters that are placed on top of the frozen 4-bit model. You can learn more about the integration of 4-bit quantized models in this blog post.
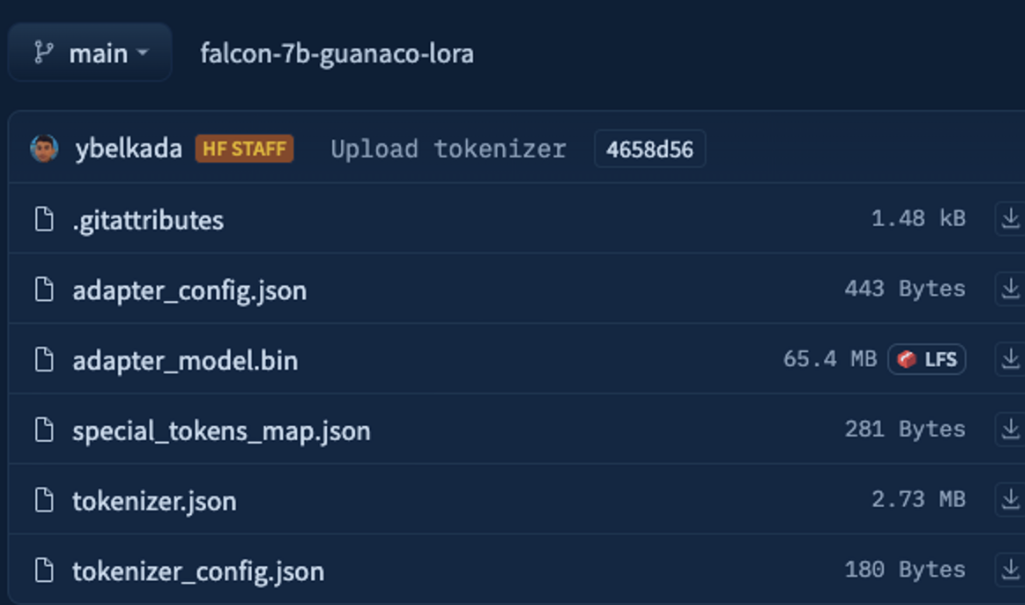
Because just a tiny fraction of the model is trainable when using Low Rank Adapters (LoRA), both the number of learned parameters and the size of the trained artifact are dramatically reduced. As shown in the screenshot below, the saved model has only 65MB for the 7B parameters model (15GB in float16).
 |
|---|
| The final repository has only 65MB of weights - compared to the original model that has approximately 15GB in half precision |
More specifically, after selecting the target modules to adapt (in practice the query / key layers of the attention module), small trainable linear layers are attached close to these modules as illustrated below). The hidden states produced by the adapters are then added to the original states to get the final hidden state.
 |
|---|
| The output activations original (frozen) pretrained weights (left) are augmented by a low rank adapter comprised of weight matrices A and B (right). |
Once trained, there is no need to save the entire model as the base model was kept frozen. In addition, it is possible to keep the model in any arbitrary dtype (int8, fp4, fp16, etc.) as long as the output hidden states from these modules are casted to the same dtype as the ones from the adapters - this is the case for bitsandbytes modules (Linear8bitLt and Linear4bit ) that return hidden states with the same dtype as the original unquantized module.
We fine-tuned the two variants of the Falcon models (7B and 40B) on the Guanaco dataset. We fine-tuned the 7B model on a single NVIDIA-T4 16GB, and the 40B model on a single NVIDIA A100 80GB. We used 4bit quantized base models and the QLoRA method, as well as the recent SFTTrainer from the TRL library.
The full script to reproduce our experiments using PEFT is available here, but only a few lines of code are required to quickly run the SFTTrainer (without PEFT for simplicity):
from datasets import load_dataset
from trl import SFTTrainer
from transformers import AutoTokenizer, AutoModelForCausalLM
dataset = load_dataset("imdb", split="train")
model_id = "tiiuae/falcon-7b"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(model_id, trust_remote_code=True)
trainer = SFTTrainer(
model,
tokenizer=tokenizer,
train_dataset=dataset,
dataset_text_field="text",
max_seq_length=512,
)
trainer.train()
Check out the original qlora repository for additional details about evaluating the trained models.
Fine-tuning Resources
- Colab notebook to fine-tune Falcon-7B on Guanaco dataset using 4bit and PEFT
- Training code
- 40B model adapters (logs)
- 7B model adapters (logs)
Conclusion
Falcon is an exciting new large language model which can be used for commercial applications. In this blog post we showed its capabilities, how to run it in your own environment and how easy to fine-tune on custom data within in the Hugging Face ecosystem. We are excited to see what the community will build with it!

