

Update README.md
Browse files
README.md
CHANGED
|
@@ -13,7 +13,7 @@ pipeline_tag: visual-question-answering
|
|
| 13 |
# paligemma-3b-ft-docvqa-896-lora
|
| 14 |
|
| 15 |
|
| 16 |
-
**paligemma-3b-ft-docvqa-896-lora** is a fine-tuned version of the **[google/paligemma-3b-ft-docvqa-896](https://huggingface.co/google/paligemma-3b-ft-docvqa-896)** model, specifically trained on the **[doc-vqa](https://huggingface.co/datasets/cmarkea/doc-vqa)** dataset published by
|
| 17 |
|
| 18 |
During training, particular attention was given to linguistic balance, with a focus on French. The model was exposed to a predominantly French context, with a 70% likelihood of interacting with French questions/answers for a given image. It operates exclusively in bfloat16 precision, optimizing computational resources. The entire training process took 3 week on a single A100 40GB.
|
| 19 |
|
|
@@ -74,7 +74,7 @@ with torch.inference_mode():
|
|
| 74 |
|
| 75 |
### Results
|
| 76 |
|
| 77 |
-
By following the **LLM-as-Juries** evaluation method, the following results were obtained using three judge models (GPT-4o, Gemini1.5 Pro and Claude 3.5-Sonnet). These models were evaluated based on
|
| 78 |
|
| 79 |
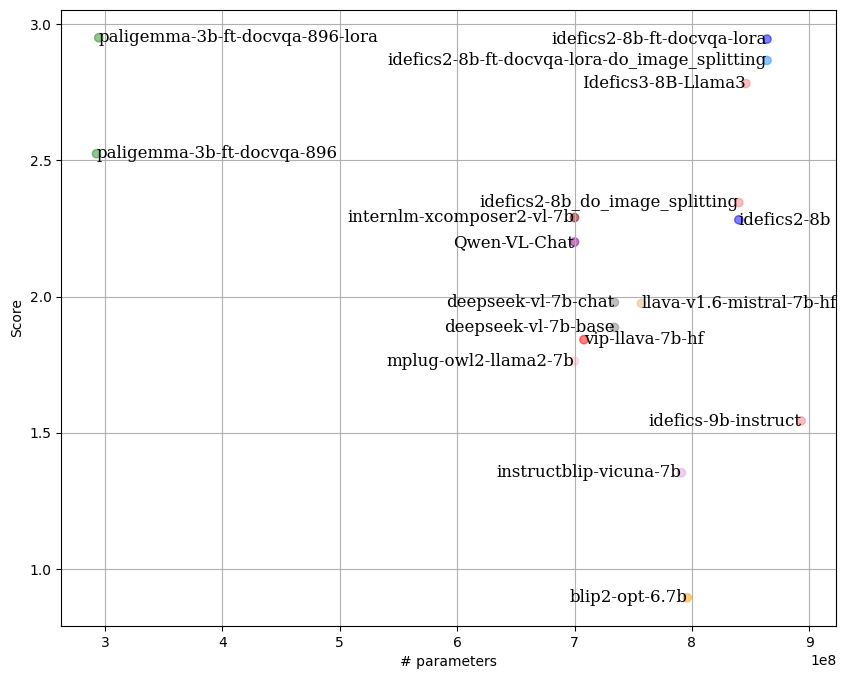
|
| 80 |
|
|
|
|
| 13 |
# paligemma-3b-ft-docvqa-896-lora
|
| 14 |
|
| 15 |
|
| 16 |
+
**paligemma-3b-ft-docvqa-896-lora** is a fine-tuned version of the **[google/paligemma-3b-ft-docvqa-896](https://huggingface.co/google/paligemma-3b-ft-docvqa-896)** model, specifically trained on the **[doc-vqa](https://huggingface.co/datasets/cmarkea/doc-vqa)** dataset published by Crédit Mutuel Arkéa. Optimized using the **LoRA** (Low-Rank Adaptation) method, this model was designed to enhance performance while reducing the complexity of fine-tuning.
|
| 17 |
|
| 18 |
During training, particular attention was given to linguistic balance, with a focus on French. The model was exposed to a predominantly French context, with a 70% likelihood of interacting with French questions/answers for a given image. It operates exclusively in bfloat16 precision, optimizing computational resources. The entire training process took 3 week on a single A100 40GB.
|
| 19 |
|
|
|
|
| 74 |
|
| 75 |
### Results
|
| 76 |
|
| 77 |
+
By following the **LLM-as-Juries** evaluation method, the following results were obtained using three judge models (GPT-4o, Gemini1.5 Pro and Claude 3.5-Sonnet). These models were evaluated based on the average of two criteria: response accuracy and completeness, similar to what the [SSA metric](https://arxiv.org/abs/2001.09977) aims to capture. This metric was adapted to the VQA context, with clear criteria for each score (0 to 5) to ensure the highest possible precision in meeting expectations.
|
| 78 |
|
| 79 |

|
| 80 |
|