---
license: cc-by-nc-nd-4.0
language:
- zh
datasets:
- MIRACL
tags:
- miniMiracle
- passage-retrieval
- knowledge-distillation
- middle-training
pretty_name: >-
miniMiracle is a family of High-quality, Light Weight and Easy deploy
multilingual embedders / retrievers, primarily focussed on Indo-Aryan and
Indo-Dravidin Languages.
library_name: transformers
pipeline_tag: sentence-similarity
---


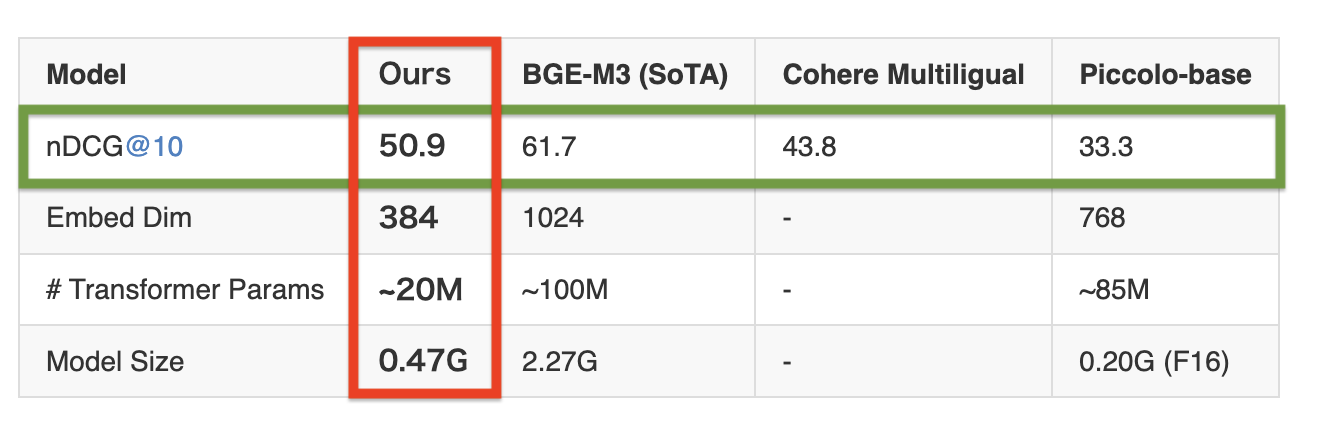
Table 1: Chinese retrieval performance on the MIRACL dev set (measured by nDCG@10)
Table Of Contents
- [License and Terms:](#license-and-terms)
- [Detailed comparison & Our Contribution:](#detailed-comparison--our-contribution)
- [ONNX & GGUF Variants:](#detailed-comparison--our-contribution)
- [Usage:](#usage)
- [With Sentence Transformers:](#with-sentence-transformers)
- [With Huggingface Transformers:](#with-huggingface-transformers)
- [How do I optimise vector index cost?](#how-do-i-optimise-vector-index-cost)
- [How do I offer hybrid search to address Vocabulary Mismatch Problem?](#how-do-i-offer)
- [Notes on Reproducing:](#notes-on-reproducing)
- [Reference:](#reference)
- [Note on model bias](#note-on-model-bias)
## License and Terms:
 ## Detailed comparison & Our Contribution:
English language famously have **all-minilm** series models which were great for quick experimentations and for certain production workloads. The Idea is to have same for the other popular langauges, starting with Indo-Aryan and Indo-Dravidian languages. Our innovation is in bringing high quality models which easy to serve and embeddings are cheaper to store without ANY pretraining or expensive finetuning. For instance, **all-minilm** are finetuned on 1-Billion pairs. We offer a very lean model but with a huge vocabulary - around 250K.
We will add more details here.
## Detailed comparison & Our Contribution:
English language famously have **all-minilm** series models which were great for quick experimentations and for certain production workloads. The Idea is to have same for the other popular langauges, starting with Indo-Aryan and Indo-Dravidian languages. Our innovation is in bringing high quality models which easy to serve and embeddings are cheaper to store without ANY pretraining or expensive finetuning. For instance, **all-minilm** are finetuned on 1-Billion pairs. We offer a very lean model but with a huge vocabulary - around 250K.
We will add more details here.
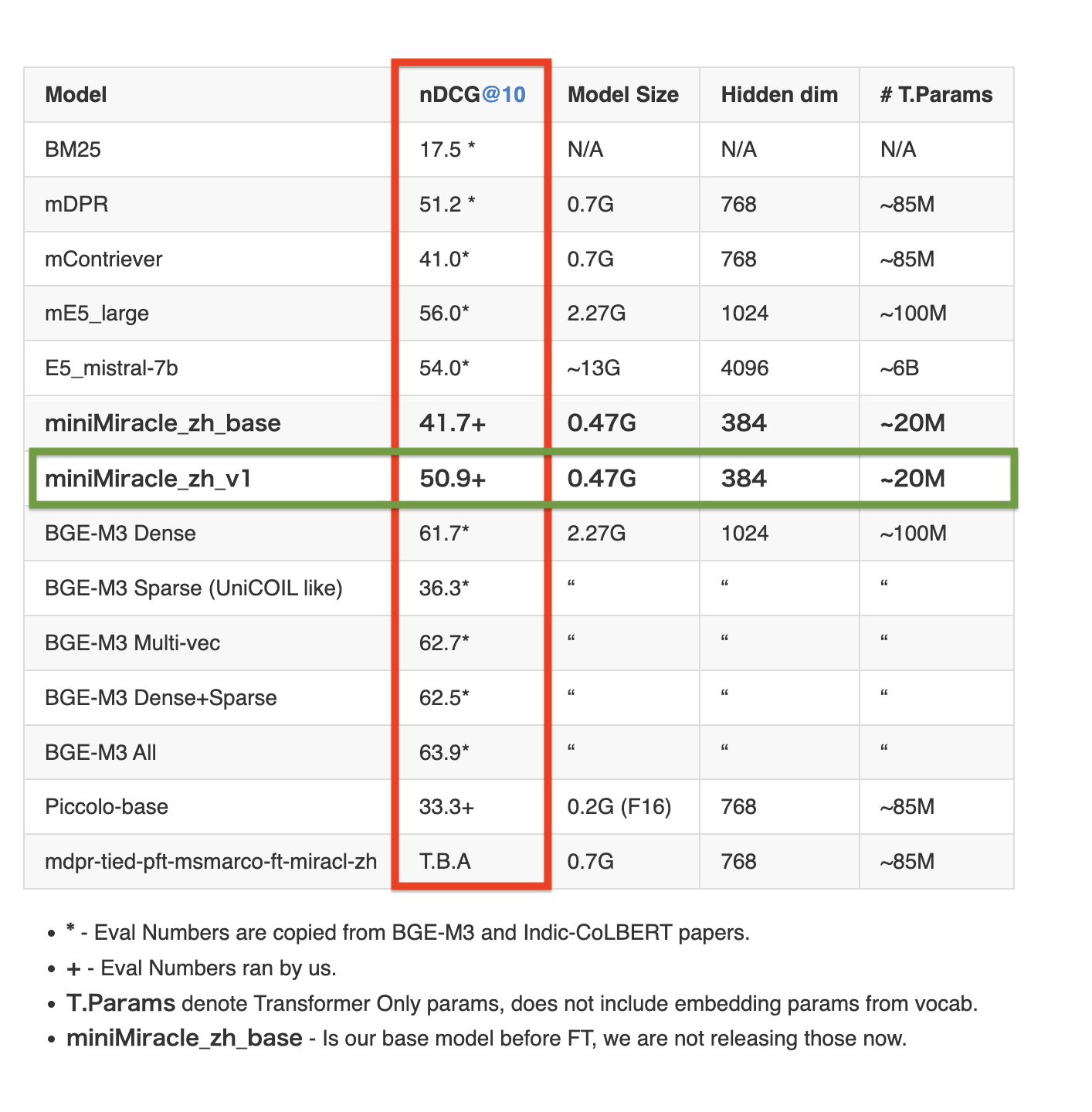
Table 2: Detailed Chinese retrieval performance on the MIRACL dev set (measured by nDCG@10)
Full set of evaluation numbers for our model
```python
{'NDCG@1': 0.43511, 'NDCG@3': 0.42434, 'NDCG@5': 0.45298, 'NDCG@10': 0.50914, 'NDCG@100': 0.5815, 'NDCG@1000': 0.59392}
{'MAP@1': 0.21342, 'MAP@3': 0.32967, 'MAP@5': 0.36798, 'MAP@10': 0.39908, 'MAP@100': 0.42592, 'MAP@1000': 0.42686}
{'Recall@10': 0.63258, 'Recall@50': 0.85, 'Recall@100': 0.91595, 'Recall@200': 0.942, 'Recall@500': 0.96924, 'Recall@1000': 0.9857}
{'P@1': 0.43511, 'P@3': 0.29177, 'P@5': 0.22545, 'P@10': 0.14758, 'P@100': 0.02252, 'P@1000': 0.00249}
{'MRR@10': 0.55448, 'MRR@100': 0.56288, 'MRR@1000': 0.56294}
```
## Usage:
#### With Sentence Transformers:
```python
from sentence_transformers import SentenceTransformer
import scipy.spatial
model = SentenceTransformer('prithivida/miniMiracle_zh_v1')
corpus = [
'一个男人正在吃东西',
'人们正在吃一块面包',
'女孩抱着婴儿',
'一个男人正在骑马',
'一个女人正在弹吉他',
'两个人推着马车穿过树林',
'一个人骑着一匹白马在一个封闭的田野里',
'一只猴子在打鼓',
'一只猎豹正在猎物后面奔跑',
'他们享受了一顿美味的盛宴'
]
queries = [
'一个人在吃意大利面',
'一个穿着大猩猩服装的人在打鼓'
]
corpus_embeddings = model.encode(corpus)
query_embeddings = model.encode(queries)
# Find the closest 3 sentences of the corpus for each query sentence based on cosine similarity
closest_n = 3
for query, query_embedding in zip(queries, query_embeddings):
distances = scipy.spatial.distance.cdist([query_embedding], corpus_embeddings, "cosine")[0]
results = zip(range(len(distances)), distances)
results = sorted(results, key=lambda x: x[1])
print("\n======================\n")
print("Query:", query)
print("\nTop 3 most similar sentences in corpus:\n")
for idx, distance in results[0:closest_n]:
print(corpus[idx].strip(), "(Score: %.4f)" % (1-distance))
# Optional: How to quantize the embeddings
# binary_embeddings = quantize_embeddings(embeddings, precision="ubinary")
```
#### With Huggingface Transformers:
- T.B.A
#### How do I optimise vector index cost ?
[Use Binary and Scalar Quantisation](https://huggingface.co/blog/embedding-quantization)
How do I offer hybrid search to address Vocabulary Mismatch Problem?
MIRACL paper shows simply combining BM25 is a good starting point for a Hybrid option:
The below numbers are with mDPR model, but miniMiracle_zh_v1 should give a even better hybrid performance.
| Language | ISO | nDCG@10 BM25 | nDCG@10 mDPR | nDCG@10 Hybrid |
|-----------|-----|--------------|--------------|----------------|
| **Chinese** | **zh** | **0.175** | **0.512** | **0.526** |
*Note: MIRACL paper shows a different (higher) value for BM25 Chinese, So we are taking that value from BGE-M3 paper, rest all are form the MIRACL paper.*
# Notes on reproducing:
We welcome anyone to reproduce our results. Here are some tips and observations:
- Use CLS Pooling and Inner Product.
- There *may be* minor differences in the numbers when reproducing, for instance BGE-M3 reports a nDCG@10 of 59.3 for MIRACL hindi and we Observed only 58.9.
Here are our numbers for the full hindi run on BGE-M3
```python
{'NDCG@1': 0.49714, 'NDCG@3': 0.5115, 'NDCG@5': 0.53908, 'NDCG@10': 0.58936, 'NDCG@100': 0.6457, 'NDCG@1000': 0.65336}
{'MAP@1': 0.28845, 'MAP@3': 0.42424, 'MAP@5': 0.46455, 'MAP@10': 0.49955, 'MAP@100': 0.51886, 'MAP@1000': 0.51933}
{'Recall@10': 0.73032, 'Recall@50': 0.8987, 'Recall@100': 0.93974, 'Recall@200': 0.95763, 'Recall@500': 0.97813, 'Recall@1000': 0.9902}
{'P@1': 0.49714, 'P@3': 0.33048, 'P@5': 0.24629, 'P@10': 0.15543, 'P@100': 0.0202, 'P@1000': 0.00212}
{'MRR@10': 0.60893, 'MRR@100': 0.615, 'MRR@1000': 0.6151}
```
Fair warning BGE-M3 is $ expensive to evaluate, probably that's why it's not part of any of the MTEB benchmarks.
# Reference:
- [All Cohere numbers are copied form here](https://huggingface.co/datasets/Cohere/miracl-en-queries-22-12)
# Note on model bias:
- Like any model this model might carry inherent biases from the base models and the datasets it was pretrained and finetuned on. Please use responsibly.