
Dataset Card
Dataset will be released soon! (most likely within a week!)
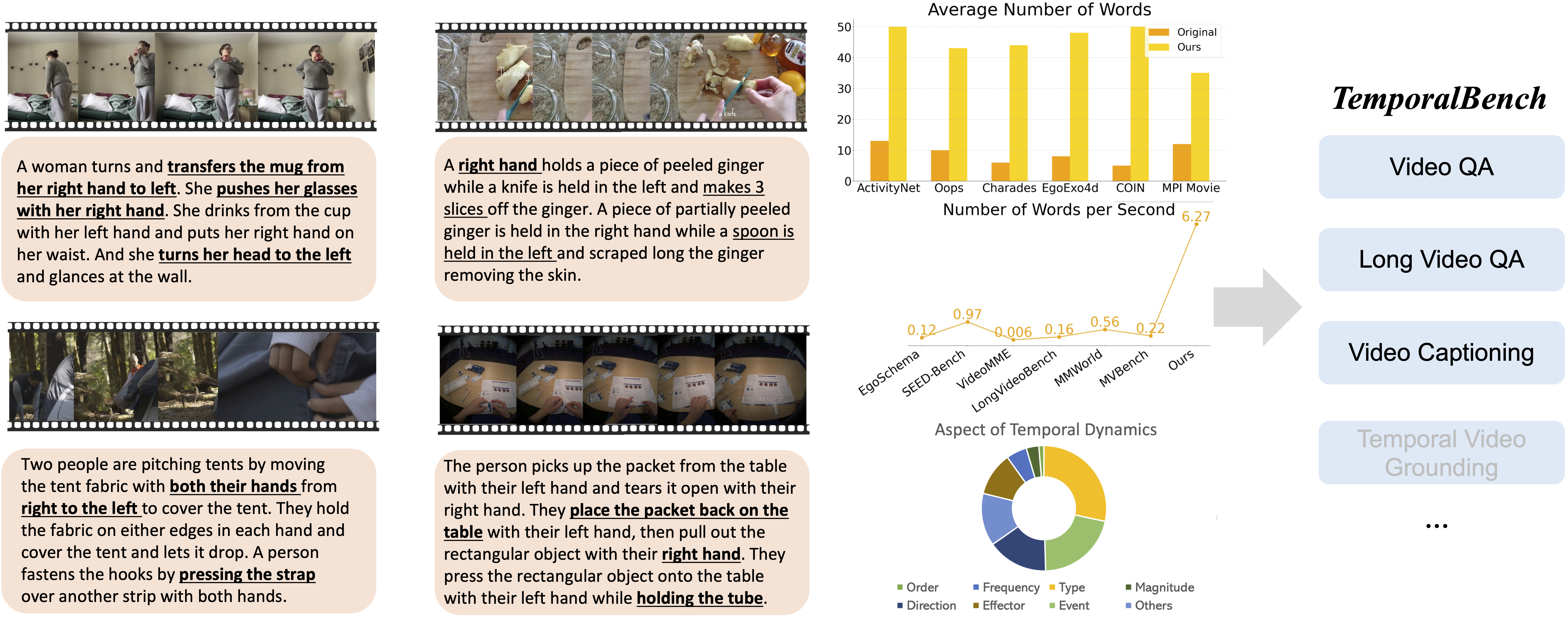
TemporalBench is a video understanding benchmark designed to evaluate fine-grained temporal reasoning for multimodal video models. It consists of ∼10K video question-answer pairs sourced from ∼2K high-quality human-annotated video captions, capturing detailed temporal dynamics and actions.
Dataset Sources
Direct Use
The dataset is useful for assessing the temporal reasoning abilities of multimodal models, particularly fine-grained video understanding, long-term video understanding, and video captioning with rich details.
Out-of-Scope Use
The dataset is not intended for use in non-temporal video tasks.
Dataset Structure
Data Instances
Each data instance in the dataset consists of a question-answer pair based on a video clip. Below is an example from the dataset:
{
'video_id': 'Charades/EEVD3_start_11.4_end_16.9.mp4',
'question': "Which caption best describes this video?\nA. A person closes the door of the fridge with his left hand while looking at the bowl of fruit he holds in his right hand. He transfers the bowl from his right hand to his left hand. He picks up a fruit from the bowl with his left hand. He tosses the fruit up with his left hand and catches it with the same hand while walking forward. \nB. A person closes the door of the fridge with his left hand while looking at the bowl of fruit he holds in his right hand. He transfers the bowl from his right hand to his left hand. He picks up a fruit from the bowl with his right hand. He tosses the fruit up with his right hand and catches it with the same hand while walking forward.\nAnswer with the option's letter from the given choices directly.",
'answer': 'A'
}
Data Fields
video_id: A string representing the video identifier.question: A string containing the question related to the video.answer: A string containing the correct answer.
Data Splits
The dataset is split into the following:
val: 4933 rowstest: 4934 rows
Dataset Creation
This dataset was created from human annotators with fine-grained temporal annotations. The videos were sampled from various sources, including procedural videos and human activities.
Source Data
- ActivityNet-Captions, COIN, Charades-STA, FineGym, Oops, Movei Description, EgoExo4d,
Data Collection and Processing
Refer to the main paper for detailed information about the data collection and curation process.
Personal and Sensitive Information
No personal or sensitive information is contained in this dataset.
Bias, Risks, and Limitations
TemporalBench is made for academic research purposes only. Commercial use in any form is strictly prohibited. The copyright of all videos belong to their respective owners. We do not own any of the videos. Any form of unauthorized distribution, publication, copying, dissemination, or modifications made over TemporalBench in part or in whole is strictly prohibited. You cannot access our dataset unless you comply to all the above restrictions and also provide your information for legal purposes. This dataset is foucsing on fine-grained temporal tasks rather than coarse-grained video understanding.
Citation
If you find this work useful, please cite:
@article{cai2024temporalbench,
title={TemporalBench: Towards Fine-grained Temporal Understanding for Multimodal Video Models},
author={Cai, Mu and Tan, Reuben and Zhang, Jianrui and Zou, Bocheng and Zhang, Kai and Yao, Feng and Zhu, Fangrui and Gu, Jing and Zhong, Yiwu and Shang, Yuzhang and Dou, Yao and Park, Jaden and Gao, Jianfeng and Lee, Yong Jae and Yang, Jianwei},
journal={arXiv preprint arXiv:2410.10818},
year={2024}
}
- Downloads last month
- 0