
NuExtract
Collection
3 items
•
Updated
•
3
NuExtract-large is a version of phi-3-small, fine-tuned on a private high-quality synthetic dataset for information extraction. To use the model, provide an input text (less than 2000 tokens) and a JSON template describing the information you need to extract.
Note: This model is purely extractive, so all text output by the model is present as is in the original text. You can also provide an example of output formatting to help the model understand your task more precisely.
Try the base model here: https://huggingface.co/spaces/numind/NuExtract
We also provide a tiny (0.5B) and base (3.8B) version of this model: NuExtract-tiny and NuExtract
Checkout other models by NuMind:
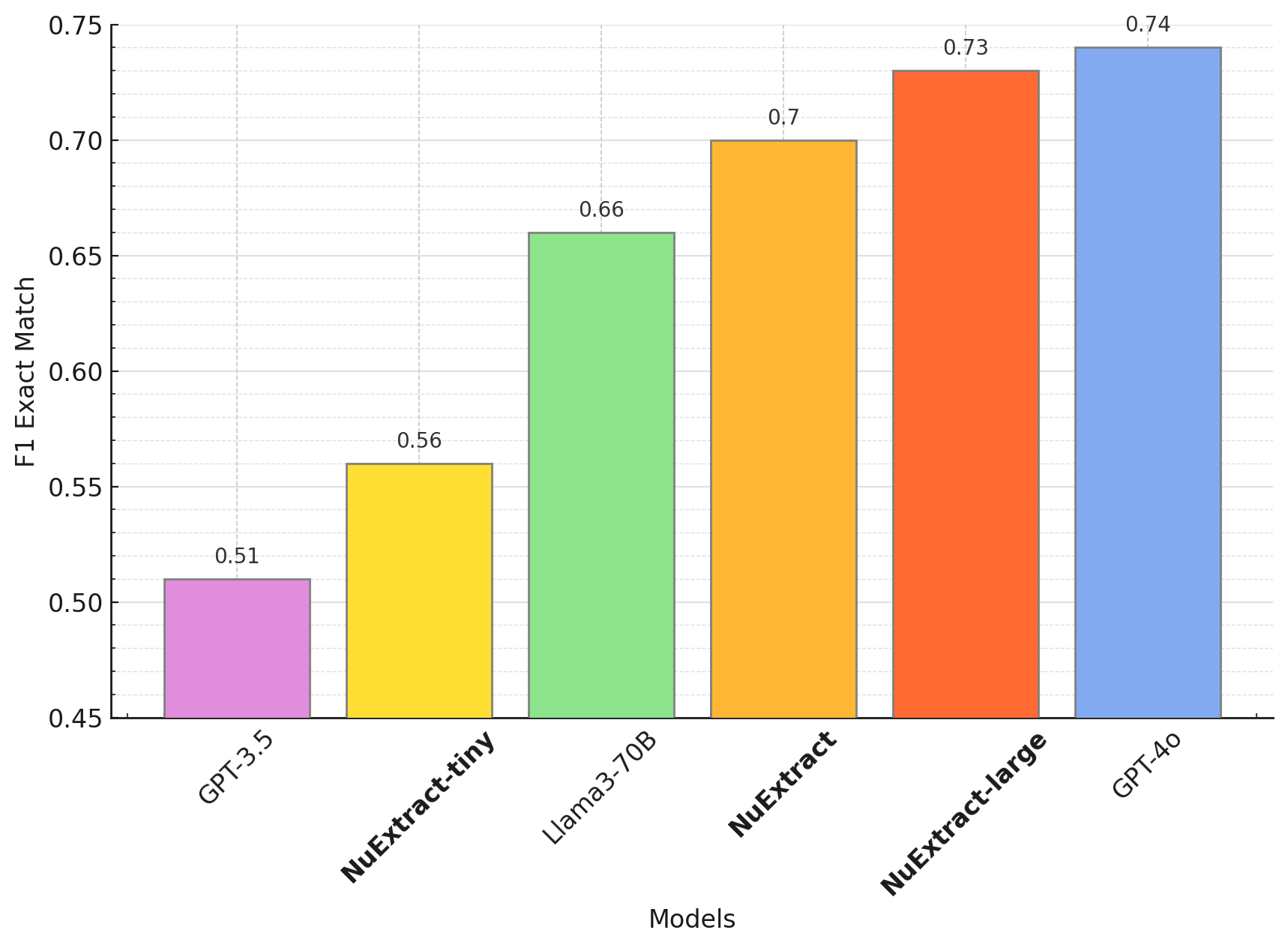
Benchmark 0 shot (will release soon):
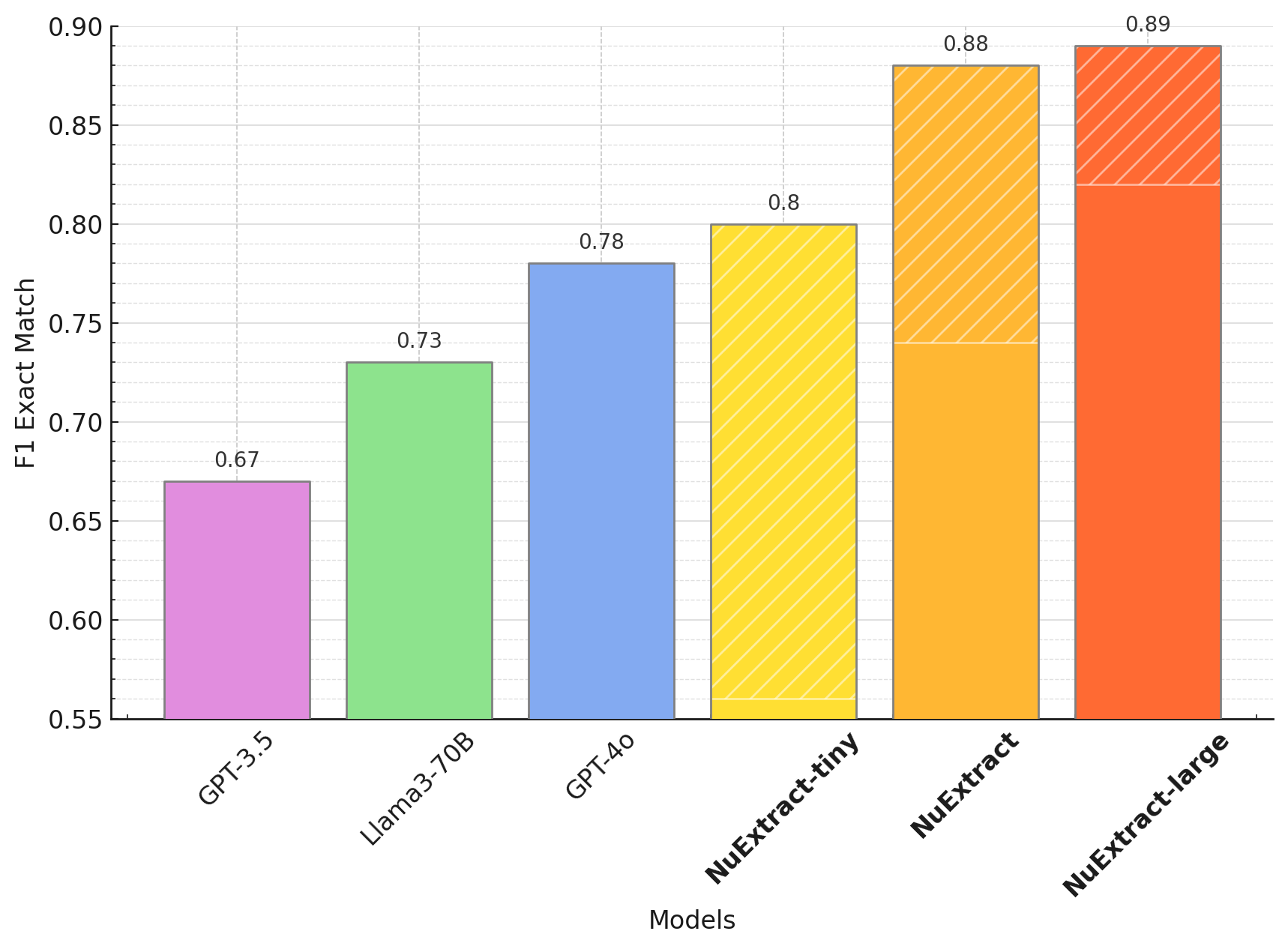
Benchmark fine-tunning (see blog post):
To use the model:
import json
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
def predict_NuExtract(model, tokenizer, text, schema, example=["","",""]):
schema = json.dumps(json.loads(schema), indent=4)
input_llm = "<|input|>\n### Template:\n" + schema + "\n"
for i in example:
if i != "":
input_llm += "### Example:\n"+ json.dumps(json.loads(i), indent=4)+"\n"
input_llm += "### Text:\n"+text +"\n<|output|>\n"
input_ids = tokenizer(input_llm, return_tensors="pt", truncation=True, max_length=4000).to("cuda")
output = tokenizer.decode(model.generate(**input_ids)[0], skip_special_tokens=True)
return output.split("<|output|>")[1].split("<|end-output|>")[0]
model = AutoModelForCausalLM.from_pretrained("numind/NuExtract", trust_remote_code=True, torch_dtype=torch.bfloat16)
tokenizer = AutoTokenizer.from_pretrained("numind/NuExtract", trust_remote_code=True)
model.to("cuda")
model.eval()
text = """We introduce Mistral 7B, a 7–billion-parameter language model engineered for
superior performance and efficiency. Mistral 7B outperforms the best open 13B
model (Llama 2) across all evaluated benchmarks, and the best released 34B
model (Llama 1) in reasoning, mathematics, and code generation. Our model
leverages grouped-query attention (GQA) for faster inference, coupled with sliding
window attention (SWA) to effectively handle sequences of arbitrary length with a
reduced inference cost. We also provide a model fine-tuned to follow instructions,
Mistral 7B – Instruct, that surpasses Llama 2 13B – chat model both on human and
automated benchmarks. Our models are released under the Apache 2.0 license.
Code: https://github.com/mistralai/mistral-src
Webpage: https://mistral.ai/news/announcing-mistral-7b/"""
schema = """{
"Model": {
"Name": "",
"Number of parameters": "",
"Number of token": "",
"Architecture": []
},
"Usage": {
"Use case": [],
"Licence": ""
}
}"""
prediction = predict_NuExtract(model, tokenizer, text, schema, example=["","",""])
print(prediction)